CDT Blog- Keiran Suchak
The first semester of the Doctoral program has been busier than I think most of the Leeds cohort of the CDT were expecting. With commitments to a module on Research Methods, demonstrating courses for undergraduates and working on the assignments for Andy Evans’ programming module, each of us looked forward to the end of semester. With the end of term came an end to taught modules, as well as an outflux of the university’s undergraduate population. This also coincided with a visit from members of the Office of National Statistics, who operated a Safe Researcher Training course. The aim of the course was to educate on the ethics of working with social data, the risks involved and how these could be mitigated. The day-long course was very interactive, and was liberally scattered with group exercises that allowed us to further explore the ideas that were presented, as well as challenging our own preconceived ideas.
The end of term also freed up time to organize a first meeting with my external project partner – Leeds City Council. Up until this point, I had been predominantly focused on the academic aspects of my project – the mathematics, the programming, the data analysis – that my brain had been trained to see over the course of my degrees in Physics and Mathematics. However, it was at this meeting that it became immediately apparent how broad the scope of application of my work would be. This meeting also allowed for the discussion of the variety of data sources that would be available to me, as well as scoping out ideas for an internship project that I look forward to undertaking this semester.
Following the end of term, I travelled down to Cambridge to attend a training week run by the Academy for PhD Training in Statistics. The aim of the week was to provide two intensive courses: one on Statistical Computing and the other on Statistical Inference. This week brought together students from universities across the UK – a variety which was matched by the range of subjects in which students were doing their PhDs, from medical statistics to climate science. Learning such a volume of material in such a compressed time-period was quite a challenge, but the exceedingly high quality of lecturing and evening activities that had been organised helped to make the week a very enjoyable experience.
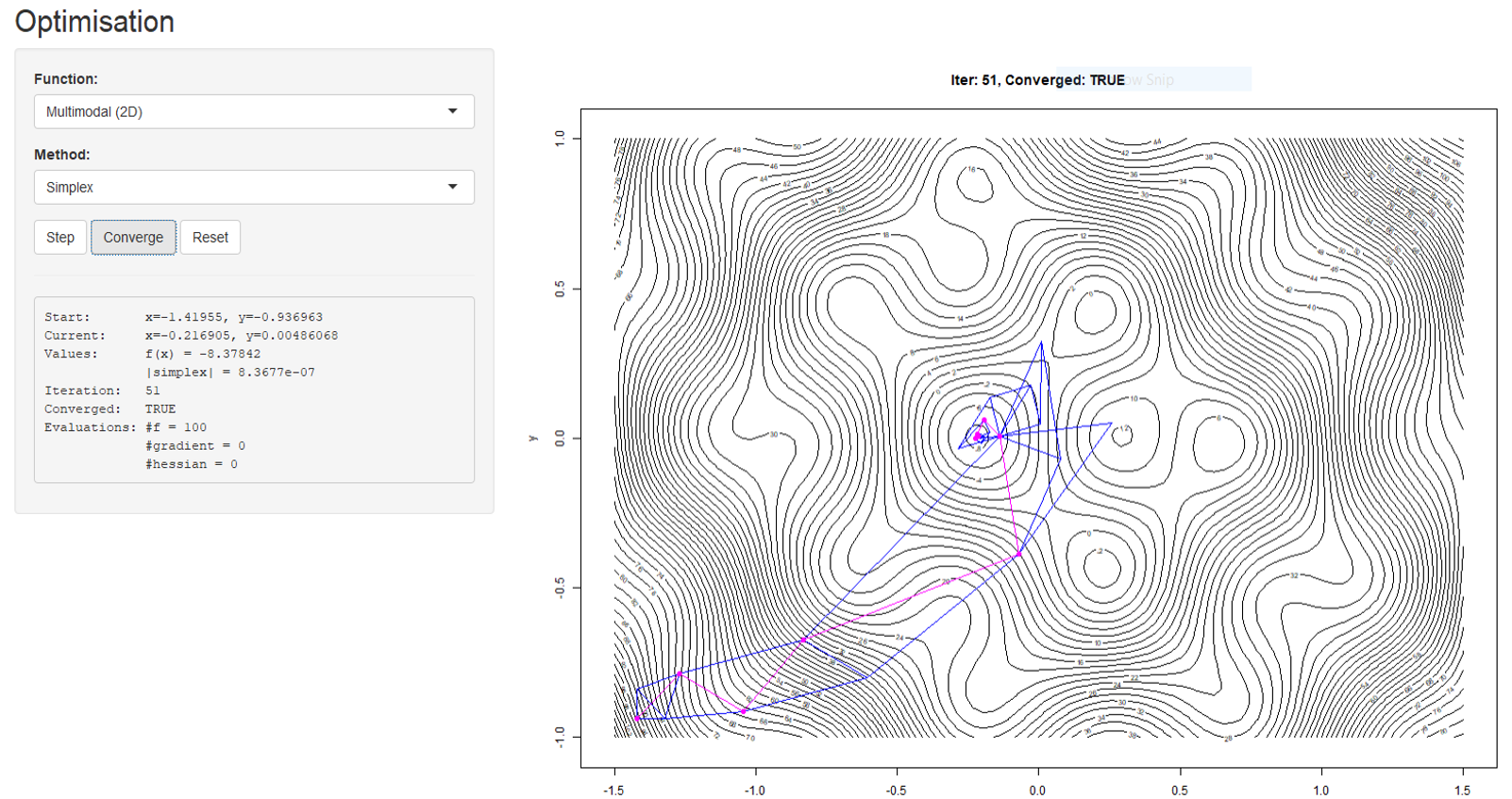
A Shiny app used on the Statistical Computing section of the courses in Cambridge, which was designed to examine the convergence of different numerical solvers.
Fortunately, this week was followed by the Christmas break – with the office closed over this period, we had no choice but to down our tools and take some well-earned rest (as well as polishing off a couple of assignments). Returning in the new year, we submitted our assignments and ventured over to Manchester for a week, where we met with the students from the other universities for the second of our joint modules. The topic of this week was Managing Data and Their Environment – a subject that we quickly learned encapsulated a wide variety of topics. The week was split into three parts: the first couple of days were devoted to the ethics and implications of using social data, the next couple of days focused more on the processes of data cleaning and linkage, and the final day was dedicated to a groupwork project whereby we could put into practice the ideas that we had learned about over the course of the week. The section on the usage of social data closely mirrored portions of the Safe Researcher Training course, and so many of the group found this to be a rather familiar exercise. The section on data cleaning and linkage, on the other hand, was found to be a little tougher owing to the volume of new information that we had to take in; I was fortunate to have spent a significant portion of the time that I was employed at Ampere Analysis working on data matching and linkage, however, there was still plenty of new material to absorb. The challenges of the days were washed away by evenings spent exploring Manchester – the highlight of which was a visit to Tampopo where we enjoyed a variety of Asian food.
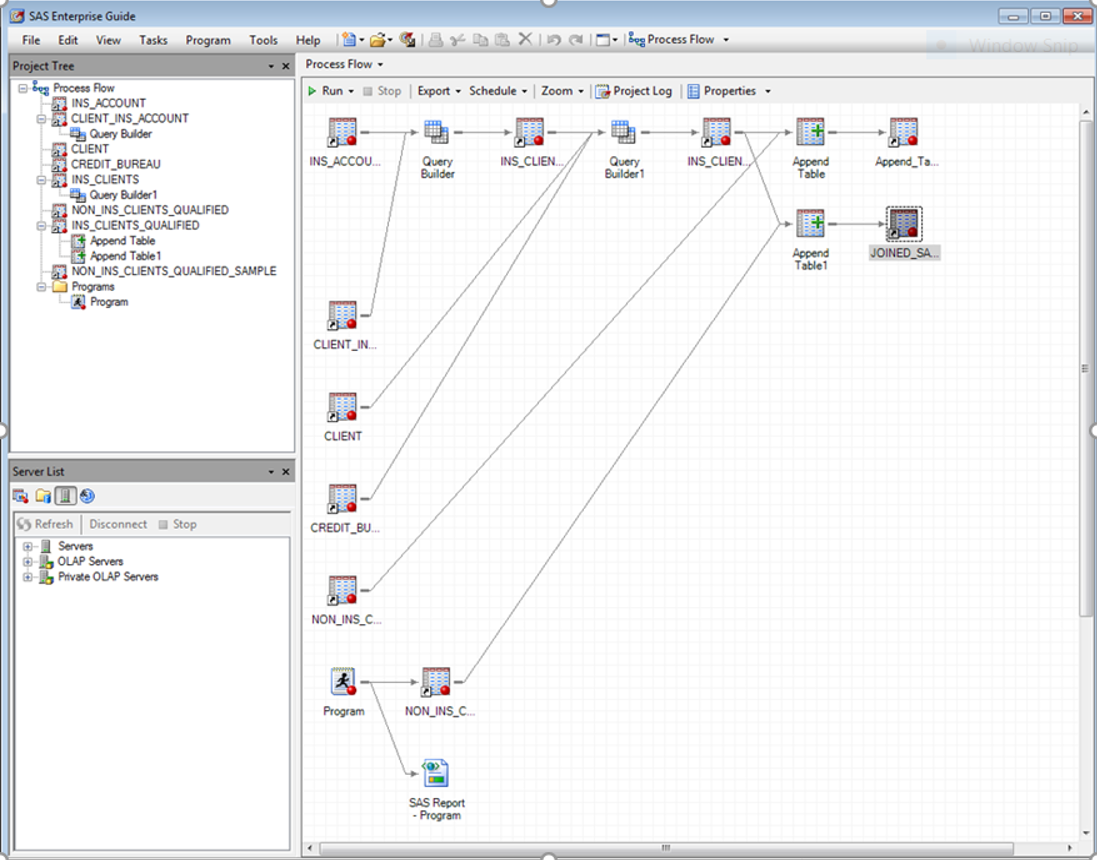
An example of the data flows created in SAS Enterprise Guide as part of the data cleaning and matching section of the Manchester module.
With the end of January comes the start of the second semester: a return to taught modules, supervisor meetings and demonstrating along with the new challenge of an internship with our respective project partners. This semester promises to be even busier than the last, however, I am sure that each of us are looking forward to the challenges that await us over the coming months.
Applications are now open for the Data Analytics and Society 2018 cohort.