From Words to Numbers – Simple NLP Techniques to Unlock the Data in Free Text
One of the most exciting and fastest growing applications of machine learning is NLP – Natural Language Processing. From the virtual assistants in our phones to the spam filters hiding behind all of our email services, NLP is integral to many of the services and applications we use every day. Though the headline-grabbing applications can be as complex as they are fascinating, you don’t need to spend months mastering LSTMs and transformer networks to use many of the powerful tools in the NLP toolkit. In this article, we’ll explore the basics of free text analysis, and see how these simple techniques were instrumental in my LIDA internship project that aims to predict treatment outcomes in a paediatric community care service.
The Task
Bradford Royal Infirmary is home to an innovative ‘hospital-at-home’ service for children and young people, called ACE – the Ambulatory Care Experience. ACE is a fantastic service that offers an alternative to hospital referral for patients that require urgent care. They treat and monitor patients in their own homes in a “virtual ward”, under the care of a consultant paediatrician. The service has been proven to significantly reduce the cost of urgent care, whilst delivering outstanding outcomes for the patients and their parents.
Key to this approach to urgent care is the triage process – determining which patients can be safely treated at home and which should be referred to hospital. ACE clinicians collect a range of clinical and non-clinical data for each referral, and use this information to make triage decisions. These decisions contribute to the successful discharge of 85% of the patients ACE treat, the other 15% requiring a subsequent referral to hospital.
The ACE team believe the referral data they collect may still contain key insights that indicate a patient’s at risk of needing hospital treatment, and propose that data science and machine learning might be the key to their discovery. To test this theory, they have partnered with ourselves at the LIDA Data Science Internship scheme and Bradford Institute for Health Research (BIHR), in a project that aims to model the outcomes of treatment in ACE – using referral data to predict which patients will require hospital treatment.
Why text analysis?
Our initial attempts to use the ACE referral data to model the risk of hospitalisation proved challenging. The referral data consist of a standard set of clinical observations that the service uses to indicate suitability for treatment at home, however the only data available for model training consist of patients that were accepted for treatment. In other words, our training data consists only of patients that were already decided to be of low risk of hospitalisation, and this decision was largely based on the observations in the training data. This makes the machine learning task extremely challenging – we are asking classification models to identify features in a dataset that trained clinicians have already tried, and failed, to find. Considering this, it is unsurprising that none of our attempts to model outcomes using the standard referral observations were successful.
Fortunately, the basic referral criteria aren’t the only data we have at our disposal. Alongside the “structured” observations in the referral data – numeric features and “tick box” categorical features – are free-hand written notes. These text features capture relevant information on patient medical histories and examinations, that aren’t captured in the observations that are recorded for every referral. Given that the information captured in these text features is absent from the standard referral criteria, it stands to reason that they aren’t considered by default when making referral decisions. As such, they have the potential to indicate hospitalisation risks that haven’t already been identified by the ACE team.
All that’s needed is a way to statistically analyse free-text.
How can you analyse text?
When we think of data, we typically think of “structured” data – forms, excel spreadsheets, company accounts – and with good reason. Structured data is recorded in a manner that is easy to analyse. Given a spreadsheet of info on 100 people with a column named “age”, the experienced among us can quickly work out their average age. Given a short 500 word bio for the same 100 people, that task would be considerably more difficult, if not impossible. Unlike structured data, determining specific information from free text is a non-trivial task, and there are no guarantees the desired information will even be present.
Fortunately modern data science has an impressive toolkit of techniques that can help us analyse text statistically. These techniques are generally captured under the umbrella of Natural Language Processing. Though the more complex applications of NLP – voice assistants, chat bots, and so on – tend to be more familiar, applications of NLP need not be so complex.
A simple application of NLP which we are all familiar with is a word cloud. The following is a word cloud generated from the “medical history” notes from the ACE data:
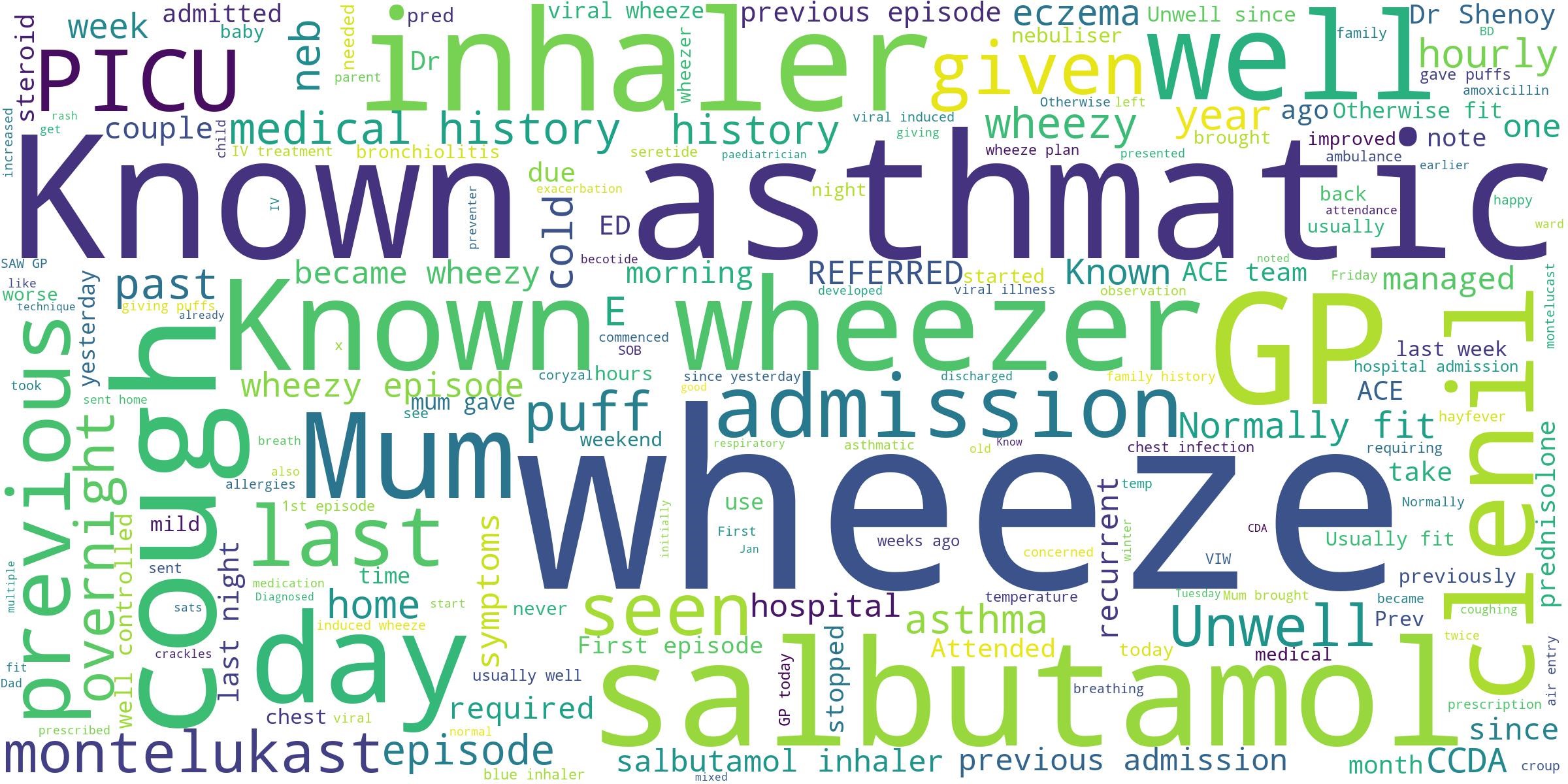
Word clouds separate text into individual (or pairs of) words, and display the most common words visually. Words that appear more often are displayed in larger font, and words appearing less often are smaller. By displaying text this way, we aim to gain an overall impression of a text or collection of texts, which words are “important” or “prominent” and which words are less so.
For example, we can see from the above word cloud, that the patients appear to be exhibiting a lot of cough or asthma symptoms. Words like “wheeze”, “inhaler”, “asthma” and “cough” are among those that stand out most clearly. We might assume, therefore, that the patients are being treated primarily for chest infections or asthma. This is an accurate interpretation of the notes, given that the ACE dataset actually describes patients that were treated on the “asthma / wheeze” pathway. We have quickly inferred some characteristics about the patients in the dataset using this simple text analysis, and our assumptions turn out to be correct.
Word clouds are a handy illustration of a methodology that underpins much of NLP – dividing text into its component parts and assigning numeric values to the parts. The word cloud quantifies the frequency with which words appear and then increases or decreases their size accordingly. This method is more commonly referred to as a “bag of words”.