Application of natural language processing for identification of online hate on Twitter
Introduction
Understanding hate crime is a priority for police forces across England and Wales. Since the EU referendum in June 2016, there has been a renewed emphasis on the importance of preventing hate crime and providing support for victims. The Home Office reported an increase of 29% in the number of hate crimes recorded between 2015-16 and 2016-17 which represents the largest increase since the Home Office began recording figures in 2011-12.
The aim of this research was to investigate whether online hate on Twitter could be used as a proxy for ‘real life’ hate happening in Lancashire. The ambition of the project was to enable Lancashire Constabulary to harness new forms of social media data (Twitter) for their own analysis of hate crime in the area – e.g. to identify possible emerging community tensions early – by applying machine learning.
Data and methods
The research was based on the spatial analysis of tweets sent by people in Lancashire during the study period (December 2015 - February 2017). These tweets were identified based on both the hometown displayed on the profile of Twitter users and the precise geotags of where the tweets were sent from. In total, 1,246,918 tweets with a hometown location and 389,410 tweets with a geotag were collected within the boundaries of Lancashire.
A classifier was built using Natural Language Processing (NLP) techniques to determine whether tweets contained hateful speech. This first involved training a machine learning algorithm with tweets that had been manually classified. The accuracy of the trained algorithm was then tested on new tweets for which the classification outcome was already known.
Once the classifier was confirmed to have a reliable level of accuracy, it was applied to the Lancashire tweets. This identified hateful tweets which were displayed on density maps at county (see Figure 1) and town level.
Key findings
This analysis revealed that it is indeed possible to create an English language classifier which accurately identifies online hate speech on Twitter.
However, the limited number of tweets with geotags identified as hateful by the classifier (see Figure 1) does not allow for as meaningful a geographical interpretation when considered at the individual town level.
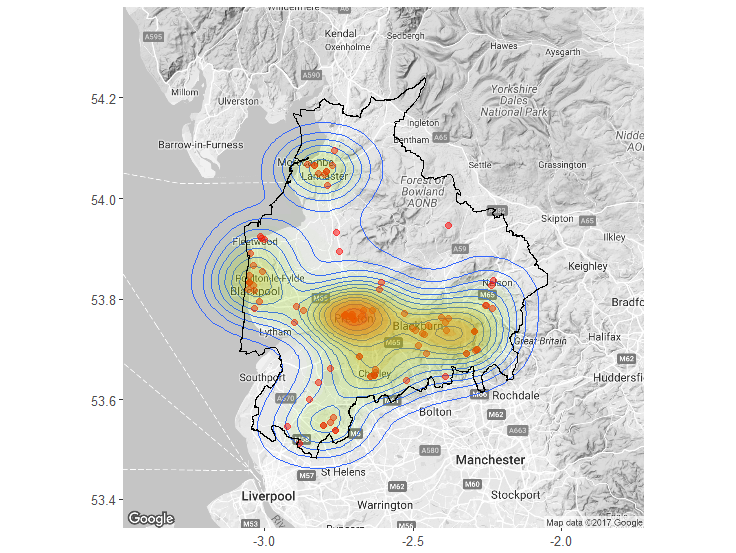
Figure 1: Density map of geotagged hateful tweets in Lancashire for the study period
Value of research
The learning from this project has emphasised the valuable information provided by social media data when dealing with under-reported crimes. Twitter produces real-time data which is helpful in generating a spatial and temporal ‘temperature check’ of different localities.
The algorithm developed in this project offers the potential to be used by Lancashire Constabulary to monitor levels of hate, thus ensuring resources can be allocated effectively to respond to emerging community tensions.
Researchers
Natacha Chenevoy - Postgraduate Data Science student, Leeds Insitute of Data Analytics
Partners
Lancashire Constabulary