Improving the speed and ease of cohort creation and analysis.
Hospitals and healthcare organisations are required to produce datasets for a variety of different reasons. Historically these datasets have been assembled without coordination or standardization. This makes combining and comparing datasets very difficult. The purpose of the Observational Medical Outcomes Partnership (OMOP) Common Data Model (CDM) is to standardize the format and content of observational datasets allowing them to be combined and queried quickly and efficiently.
An important use case of the OMOP CDM is cohort creation. When carrying out medical studies, a cohort of interested patients needs to be retrieved from the CDM. However, retrieving the correct information from a standardised database can be time consuming.
The aim of this project was to create a library that allows the creation of cohorts from the OMOP CDM. An analysis script was also developed that generates summary statistics and graphs of the selected cohort.
Data and methods
The database used for this project was a random 50k subset of the OMOP CDM. This database is comprised of many different tables with each table containing different clinical information on each individual within the database. The person table for example contains information on an individual’s age, gender, and ethnicity while the condition occurrence table contains information on an individual’s diagnosis and symptoms.
Using SQL and R, three functions were developed that retrieve cohorts of patients from the 50k database by linking the data from the different tables. The main function developed retrieves patients suffering from a certain condition such as asthma or epilepsy. The functions output either a data frame containing information on the desired cohort or an R markdown document containing low level summary statistics of the data.
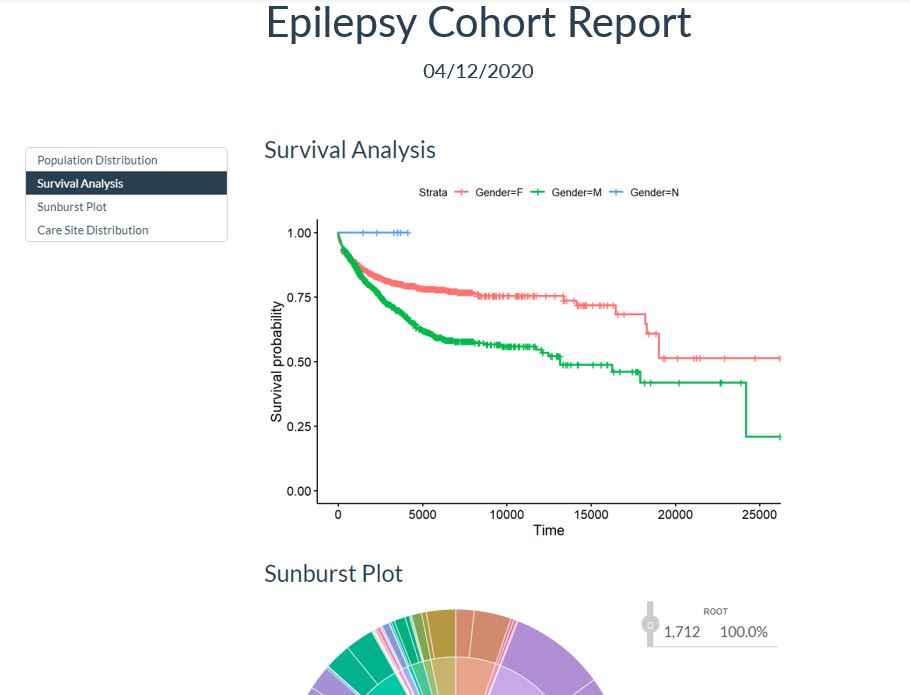
Figure 1: Example of a Cohort report generated by the functions. Includes a population distribution, survival analysis and sunburst plot of epilepsy patients as well as their care site distribution.
Key findings
The main finding was that the functions allowed for a simpler and faster way for researchers and clinicians to extract cohorts of patients from the OMOP CDM. The data frames outputted allow researchers to analyse the cohorts themselves using a tutorial document while the R markdown reports allow immediate insight into the data, particularly useful for those less familiar with R.
Value of the research
The main value of this research is the improvement in overall speed of cohort building and analysis.
“Creation of cohorts in the Connected Bradford dataset is a vital part of much of the work we are doing. Particularly in our work with the NIHR Patient Recruitment Centre it will help to improve access to research studies for all citizens of Bradford.”
Dr Tom Lawton (Bradford Institute for Health Research)
“The guidance is a valuable resource to enable researchers and analysts to access, develop and analyse patient cohorts.”
Kuldeep Sohal (Bradford Institute for Health Research)
- The OMOP common data model was developed to standardize the format and content of observational datasets allowing them to be combined and queried quickly and efficiently by researchers.
- The OMOP common data model can be used to extract cohorts of patients – but this can be time consuming and difficult for researchers less familiar with programming.
- Thus, we developed easy to use functions which allow researchers to extract cohorts of patients and output data frames or summary statistics of the data.
Research theme
- Healthcare Research
- Healthcare Informatics
People
Millie Wagstaff (LIDA Data Scientist Intern)
James Lazarus (LIDA Data Scientist Intern)
Kuldeep Sohal (Bradford Institute for Health Research)
Dr Tom Lawton (Bradford Institute for Health Research)
Funders
Bradford Institute for Health Research