Real-time Crowd Simulation Under Uncertainty using an Agent-Based Model and an Unscented Kalman Filter
Robert Clay, Prof Nick Malleson, Dr Minh Le Kieu, Dr Jon Ward - University of Leeds
We wish to apply a novel data assimilation technique (Unscented Kalman Filtering) to our Agent Based Model `StationSim’ to test its efficacy in dealing with the uncertain and aggregated data used in Smart Cities Forecasting.
Project overview
As global cities continue to grow, the management of crowds in buildings, streets, public transport terminals, stadiums, etc., becomes all the more important. Agent-based modelling (ABM) is a methodology that is ideally suited to simulating crowds of people as it captures the complex behaviours and interactions between individuals that lead to the emergence of crowding phenomena
This project begins to address this drawback by demonstrating how a data assimilation algorithm, the Unscented Kalman Filter (UKF), can be used to incorporate pseudo-real data into an agent-based model at run time. Experiments are conducted to test how well the algorithm works when some agents are tracked directly -- under varying levels of uncertainty -- and in the cases when only aggregate information about the crowd (i.e. population density) is known.
Data and methods
We generate synthetic data directly from our Agent Based Model using this as “true” data. To show the efficacy of the UKF we induce uncertainty in two experiments by partially observing our true data through random omission and aggregation respectively.
Our first experiment ignores some proportion of agents and compares errors in UKF prediction for observed agents (full positions known) vs unobserved agents (only start/end points known). This experiment allows us to simultaneously test the basic efficacy of the UKF against low uncertainty observed agents but also allows us to test its limits against high uncertainty agents as well. We vary population size and proportion of agents observed repeating the experiment for each pair of parameters 30 times taking median error results.
Our second experiment fully aggregates our position data such that all agents are unobserved and only how many agents are in each square of a grid are known (see figure 1.). This is very strong uncertainty but if successful shows strong potential for application to real data. We again vary population size but this time vary the size of the aggregated squares instead of proportion observed.
Key findings
Both experiments were highly successful and showed the UKF is effective over varying levels of uncertainty.
Results for experiment 1 has shown that the UKF can predict very well for observed agents with near uniform error over several population sizes and proportions observed (figure 2.). For unobserved agents, there are much clearer trends in error for increased population and decreased proportion observed (figure3). This suggests that the UKF is extremely effective at tracking fully observed agents under any circumstances. For unobserved agents, the proportion and population have much clearer influences and while these errors are much higher the efficacy on unobserved agents given the total lack of information is promising.
Similarly, results for experiment 2 have also shown strong promise. We have a strong increase in error with population size (figure 4.) but the size of the aggregation squares oddly seems to have no effect.
Value of the research
This research is promising for the field of smart cities technology. These strong results give a good basis to try further applications to real data. If we can produce accurate microsimulations of larger topologies it opens the way to very dynamic testing of urban infrastructure planning. If we want to redesign a train station could we test its ability to handle rush hour crowds before even placing a brick?
Insights
- The Unscented Kalman Filter is very effective at predicting agent positions in our ABM StationSim.
- We stressed the UKF with uncertain and aggregated data and still managed to see acceptable results.
- This application of a filter to aggregated data presents huge potential for a new window of research.
- The UKF seems a strong candidate for applying data assimilation techniques to real data.
Research theme
- Urban analytics
- Agent Based Modelling
- Bayesian Filtering
Partners
- LIDA
- European Research Council (ERC)
- UK Economic and Social Research Council (ESRC)
- The Alan Turing Institute
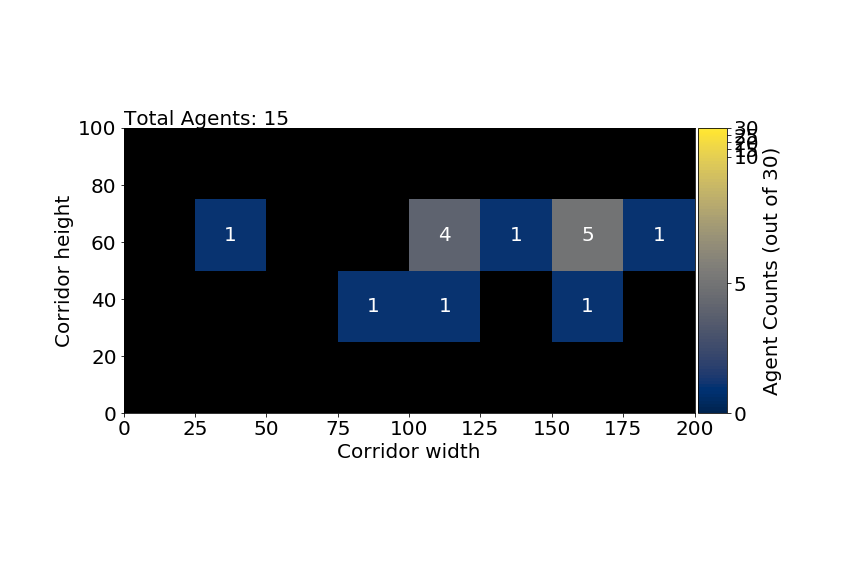
Figure 1. Aggregated data example. We have square size 25 here meaning for the 200x100 corridor we have 8x4 squares. Larger squares gives rougher aggregation and more uncertain data.
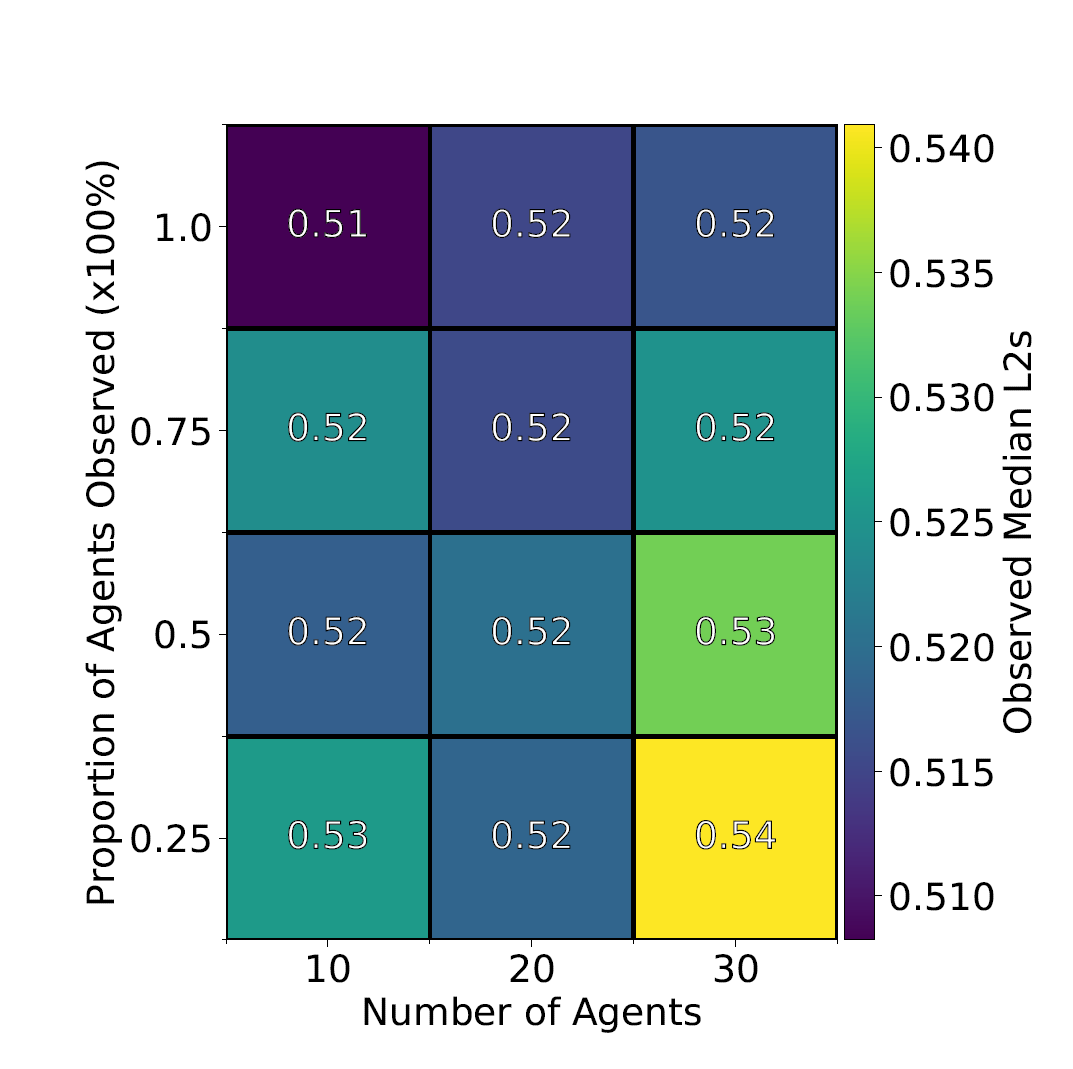
Figure 2. Observed agent UKF prediction error. Median L2 (Euclidean Error) for all agents of 30 repetitions. Only slight increases for more population/ lower proportion suggests more uncertainty.
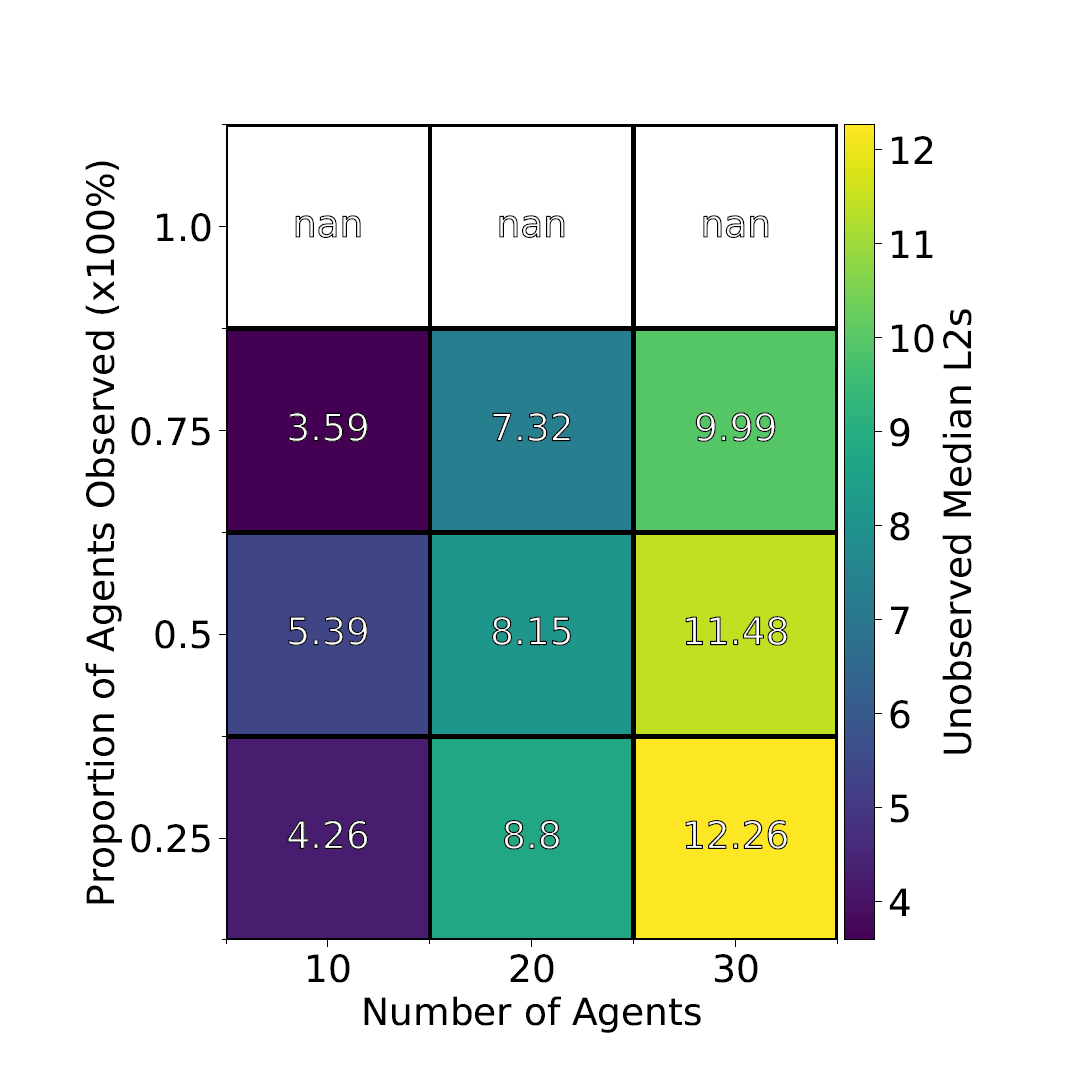
Figure 3. Unobserved agent UKF errors. Clear increase in errors given larger population and fewer agents observed. Suggests strong impact of proportion observed on ability of UKF to predict agent positions.
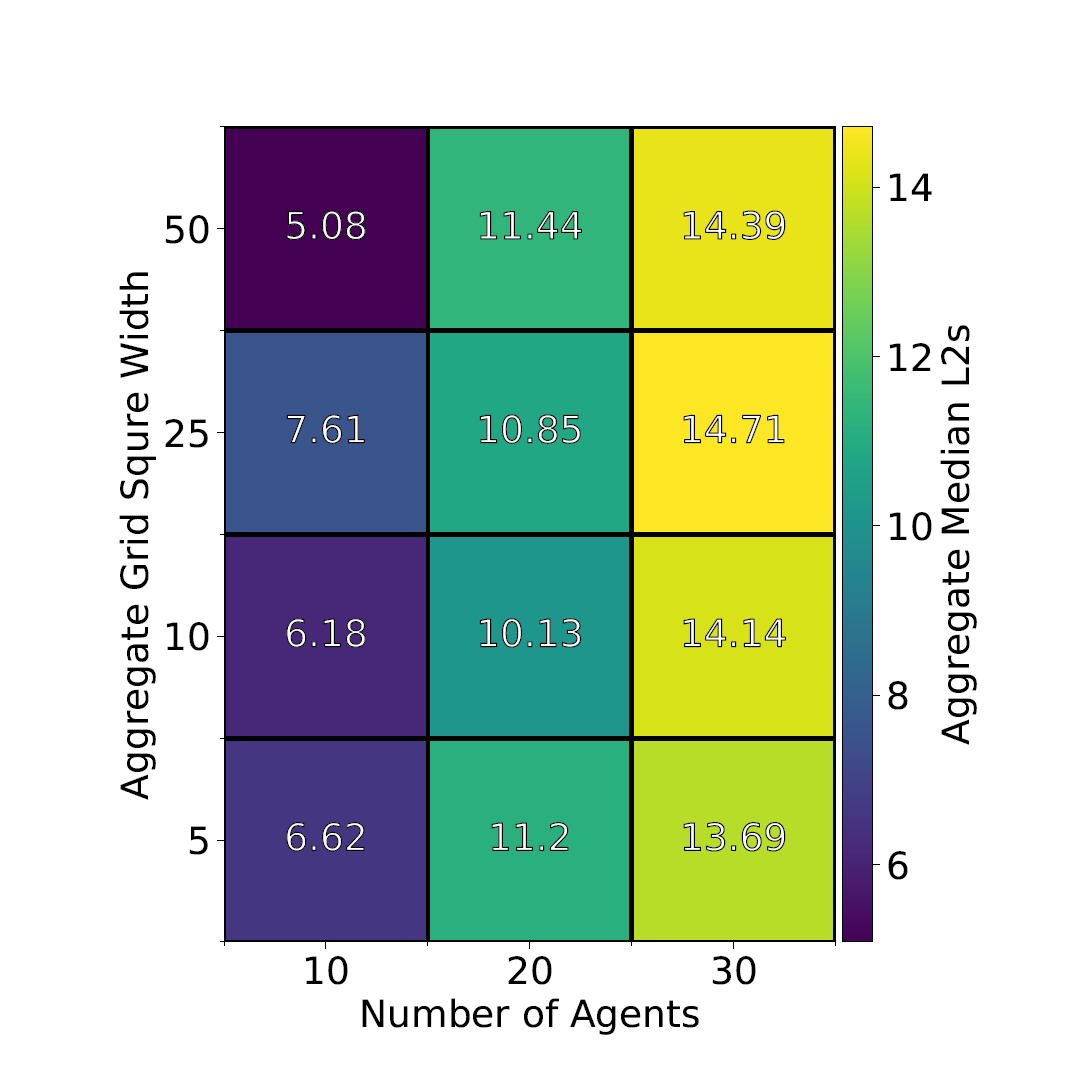
Figure 4. Aggregated UKF agent errors. Similar errors to those of unobserved agents in figure 3. Population has a clear effect on error but the size of the aggregation squares seems to have virtually no effect.
This project was undertaken as part of the LIDA Data Scientist Internship Programme.