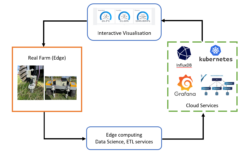
Edge-cloud service for real-time analytics of IoT-based end applications

(Sachin Ramanatha, Ali Zaidi, and Jie Xu)
Use of sensors and IoT devices for real-time remote monitoring of operational conditions and process management is an integral part of several industries like manufacturing, supply chains, automobile, packaging and many more. A similar digital infrastructure can be used to create a digital twin of a farm, where several sensors deployed on field (edge locations) measure livestock, environmental, and soil conditions. Digital services deployed on cloud can be used to analyse the recorded measurements, visualise relevant informative metrics to end users, and instruct edge devices to take predetermined actions in response to evolving conditions in real-time. This would allow remote real-time monitoring and timely management of farm with minimal human intervention. A direct impact of such a digital infrastructure would be maintenance of soil conditions to ensure good yield, which will in turn improve food security.
The goal of this research is to develop a service to remotely manage IoT devices deployed at multiple edge locations, compute and visualise various metrics related to soil conditions at a farm. Though the primary application is a digital farm, this service will implement a generic warehouse-process-visualise pipeline, which can then be adapted to meet diverse time and computational requirements of other end applications in future.
Key challenges are identified as data volume, data velocity, real-time constraints, high-availability, scalability, and security. These challenges and corresponding solutions are briefly described below –
- Data Volume – some of the IoT devices will be designed to monitor specific event at various edge locations while the others to return regular measurements. In both the cases IoT devices will generate granular data, which increases the volume of data. Different storage options such as local, cloud, and hybrid will be considered in this research to meet the data volume demands.
- Data velocity – depending on the application at edge the devices will measure variables of interest at various time intervals ranging from fraction of a second to several minutes, the smallest of which determines data velocity. Tools tailored to efficiently handle time-series data like InfluxDB will be used to accommodate high data velocities.
- Real-time demand – end applications might require monitoring, computation of specific metrics, and machine learning based predictive analytics in real-time. Tools like Grafana and Prometheus will be used in this research to visualise historical and live data. Computation of metrics and predictive analytics tasks will be distributed between edge and cloud to make the service time efficient.
- High-availability, scalability, and security – Kubernetes cluster with multiple masters and proxy will be deployed to make the service cloud agnostic, scalable, and highly available. The master and worker nodes in the cluster will be added to a virtual private network with appropriate internal IP addresses and internet gateway settings to ensure security against any unauthorised access. With all the micro-services like InfluxDB, Grafana, Prometheus being containerised and deployed on Kubernetes, provisioning new worker nodes and adding them to the existing cluster is sufficient to tailor the service to a highly demanding end application.