Spotting high-risk job ads on social media to mitigate labour exploitation

Project Overview
Millions of individuals worldwide are subjected to exploitative labour practices, highlighting the urgency of addressing modern slavery.
This project focuses on intervention at the recruitment stage, where deceptive job advertisements often proliferate unchecked.
We adopt a machine learning approach to identify high-risk online job adverts which may potentially lead to labour exploitation.
These techniques enable the identification of relevant linguistic patterns indicative of high-risk adverts.
Leveraging these features, a predictive model is trained using a random forest classifier to differentiate high-risk adverts from others. Through this approach, we aim to facilitate timely intervention to protect vulnerable job seekers from exploitation.
Data and Methods
The sample of adverts available for this project were obtained through collaboration with a non-profit organisation – these advertisements are known to have resulted in instances of labour exploitation.
The difficulty in this undertaking lies in identifying advertisements that can definitively be ruled out as non-exploitative.
Our aim to identify such deceptive advertisements is an example of ‘positive unlabelled’ (PU) learning, a type of statistical learning problem where instead of negative instances, we encounter a mix of advertisements with unknown outcomes.
Our approach is to treat the advertisements with unknown outcomes as if they were negative and to use the data in this way to train a classification model.
Relevant features were extracted from a sample of job adverts with the help of natural language processing techniques such as word embeddings. Subjectivity and polarity scores, which are typically used for sentiment analysis were extracted and evaluated to form new features, adding a sentiment element to the constructed dataset.
Using these features, a random forest classifier was trained to distinguish high-risk adverts from others. The model was validated using a different set of job adverts which are unseen to the model and hyperparameters of the model were optimised to achieve the best classification results.
Key Findings
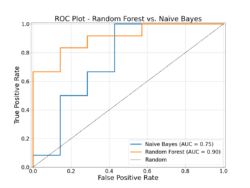
Figure 1: An ROC curve showing the performance of the random forest classification model compared to a Naïve Bayes Classifier.
Our model has a mean accuracy of 70% - it correctly identifies 77% of all positive results in the data and classifies 68% of all unlabelled instances as negative, on average.
An ROC curve was generated to illustrate the model's performance, as depicted in Figure 1. The line representing the random forest model demonstrates that at various thresholds set by individual trees within the model, at least 60% of positive results were accurately classified. Notably, the performance of the random forest model surpasses that of a previous classification attempt employing a naive Bayes classifier, and its curve exhibits significantly higher performance than what would be expected by random chance alone.
Analysing the importance of each feature to the classification model revealed the aspects of the exploitative adverts had the greatest influence over the decision made to classify an advert as exploitative or not.
A notable observation is the model’s tendency to classify a significant proportion of ‘negative’ results as potentially exploitative as evidenced by a high false positive rate. This could indicate that the model has detected deceptive features in the ‘unlabelled’ data, as intended. However, further investigation is required to determine a cause for this discrepancy.
Using random forests, it is possible to analyse the influence each feature has on the classification of an advertisement as deceptive or not. Figure 2. shows the advertisement features in decreasing importance to the decisions made by the classifier, word length is the attribute with the most influence over the classification. It is worth noting that none of the individual features have an exceptionally high influence over the classification decision, indicating a balanced model without overfitting or bias.
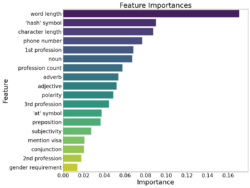
Figure 2: A bar chart showing the influence of each feature on classifications made by the random forest model.
Value of the research
Through this work we demonstrate the use of machine learning to help vulnerable job seekers by facilitating timely intervention.
Feature importance scores provide insights into which aspects of a deceptive advertisement are characteristic and worth flagging. With additional data and further exploration into these findings would allow a tool to be developed which warns potential victims by highlighting aspects of an advert that indicate exploitative practices.
A classification model has been trained and evaluated and is available for any further work to extend the number of features implemented or to be used to model a wider range of data.
This work represents a crucial step towards mitigating the risk of labour exploitation in the digital age and safeguarding the rights of workers.
Research Theme
- Societies
Programme Theme
- Statistical Data Science
- Artificial Intelligence
- Visualisation Extended Reality
- Mathematical and Computational Foundations
- Data Science Infrastructures
People
- Preeti Sharma – Data Scientist (LIDA)
- Sajid Siraj - Associate Professor, Business Analytics & Decision Sciences, Leeds University Business School, University of Leeds
- Mahnaz Hosseinzadeh - Lecturer in Operations Management and Decision Sciences at Sheffield University Management School, University of Sheffield
- Dr Amin Vafadarnikjoo - Lecturer in Operations Management and Decision Sciences at Sheffield University Management School, University of Sheffield