Uncovering behavioural patterns within spatial-temporal data using network science and unsupervised machine learning
Benjamin Isaac Wilson, Alison Heppenstall, Roger Beecham and Minh Le Kieu - University of Leeds
How can we explore for hidden patterns of behaviour in the vast amounts of available data captured by networked sensors within our cities using a combination of machine learning and network science methods?
The recent availability of big data about the individual (social data) can allow for a richer understanding of how cities work. We can use this rich data to answer questions about, for example, why spatial and non-spatial segregation into different communities can occur, why deprivation hotspots develop, and where traffic congestion is likely to happen. However, identifying when, where and why these patterns will emerge is extremely difficult. How can we explore these patterns that result from individual mobility decisions based on factors such as life stage, accessibility to workplace, shops or other facilities etc?
Project aims
This project explores how network science and unsupervised machine learning can complement each other in trying to discover patterns of movements and behaviours in geo-spatial origin-destination data. How can including individual-level features for a person’s cycle trip allow for the discovery of unexpected patterns and what challenges an exploratory analysis poses for such a problem?
Explaining the science
Bike share origin-destination data during 2017 from US cities Boston and Chicago was gathered, this offers individual attributes such as age, gender and user type (member or guest). Using this rich data, we can start factoring in how these individual attributes can influence movement behaviour around cites. T-distributed stochastic neighbour embedding was used to represent the high dimensional data in a 2D space. After which three algorithms were chosen to perform clustering;
- MiniBatch K-Means because of its general-purpose usage, popularity and performance over larger datasets;
- Density-Based Spatial Clustering of Applications with Noise for its facility to detect noise and handle non-convex clusters effectively
- Agglomerative clustering for its ability to discover varying clusters of different sizes, density and shape.
The output of each algorithm is then evaluated using silhouette coefficient which is an assessment of how well instances clearly fit inside their defined cluster. Then using a geo-spatially arranged network layout to observe and analyse the captured clusters/subgraphs using network science indicators such a degree centrality to discover where these communities frequently travel.
Sample of outputs
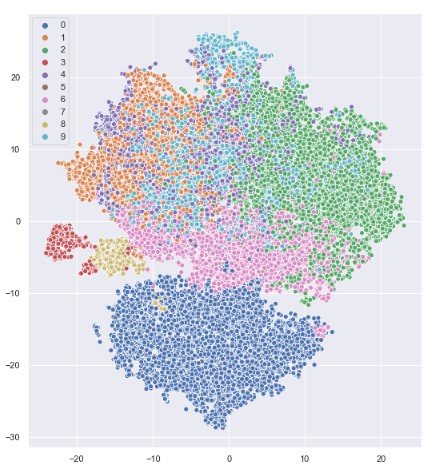
Figure 1: Result of agglomerative clustering laid over a 2D plot of the data which has been created using t-distributed stochastic neighbour embedding, a manifold dimension reduction all using the Scikit Learn python package. A Non-convex structure provides insight into what clustering algorithms may be effective.

Figure 2: The output of agglomerative clusters represented as a network describes movement of individuals moving around the university areas of Boston during working hours of the day. We naturally witness a proportionally higher number of younger users.
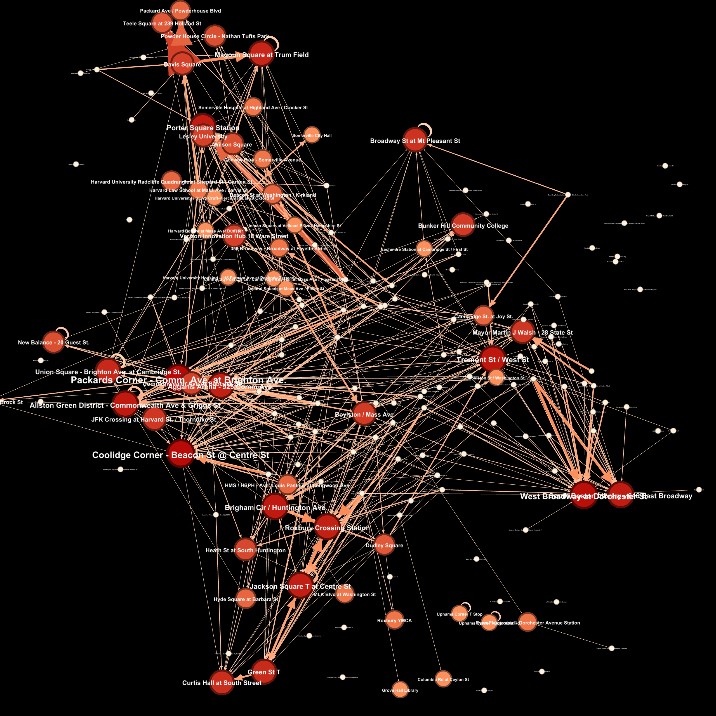
Figure 3: A cluster created using MiniBatch K-Means that describes movement in the late day. We observe users heading to major transportation hubs away from central business and academic districts within Boston.
Insights
- Clustering is capable in capturing movement behaviours though we also witness a fair amount of overlapping behaviours
- Analysis of these clusters at the micro-level may provide higher variety of behaviours in smaller areas
- The choice of n_clusters is important. We found that trying to maximise n_clusters while keeping them distinctly meaningful is a challenge but is important to obtaining the highest variety of unique behaviours
Applications
The detection or discovery of unique behaviours can lead to better design of our transportation systems. For example, one study conducted on London’s Santander bike scheme revealed differences in gender behaviours where they witnessed that women tended to prefer safer and more leisurely routes. With this information, city planners could potentially design or suggest safer routes for all individuals based on the preferred behaviours of females. If we could better understand these communities, we would better judge the way we design our urban environments.
Funders / Partners
- The Alan Turing Institute